

Smart agent solution
Current pulling monitoring logic limits
Hi,
Today we will talk about a subject that is in my mind for some months: current monitoring logic and its limits. We are using for long the pull logic, inherited from the old Nagios times. You can use poor monitoring solution like snmp based checks, a one that is a nightmare to maintain like NRPE or more advanced checks like my ssh based ones. But in the end it's mainly a protocol change, the pulling logic is the same.
That's why shinken is able to have so much pollers, to allow you to launch as much checks as you want. It works. Even on large IT if you have enough pollers you will be able to monitor what you want. But maybe it's not the most efficient way to do.
Let's look at a simple picture about our two majors monitoring problems:
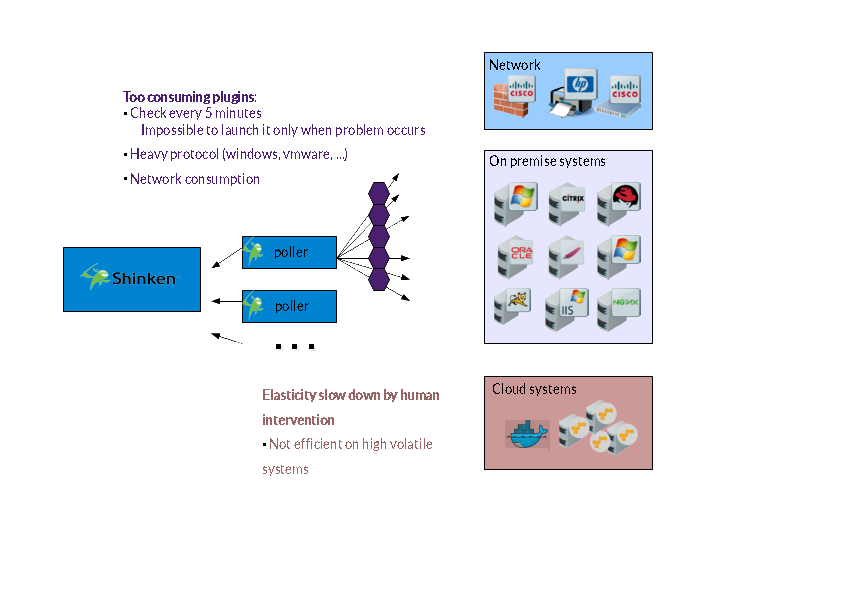
Plugin consumption
The first problem is the plugins consumption. In the most large Shinken setups, I did see overloaded pollers. But it was not the poller daemons that used all the CPUs. No. It was always the plugins. And especially vmware and Windows ones (the SOAP and WMI protocols are just too heavy). Of course you can just add new CPUs, but we should try to find a smarter solution than just adding more and more CPUs each time you are adding new servers.
This consumption is limiting us to the classic 5 minutes monitoring interval between checks. Some folks monitor some cluster each 10s, but only for a limited scope.
Need for more elasticity
The second problem is more recent. With all the Cloud based usage (I link together EC2, Openstack and Docker in this group) the elasticity became more critical than huge performances. You want your new EC2 node to be monitored as soon as it's ready, not 1 hour after. Because maybe its livespan is less than this!
Some frameworks like kubernetes can help, but such tools are quite complex and we should be able to provide simpler solutions to common cases.
My solution
Smart agent
During years, agentless monitoring was king. Because polling was acceptable from a CPU point of view, and elasticity was an exception, not the rule. Managing agents was a nightmare because they did only follow central server questions and did not try to be smart (believe me, NRPE is NOT smart at all).
But if you have a smart agent, that doesn't only launch a check when asked, but instead try to detect the server "tags" where it is installed, where it can collect both system and applications properties and metrics (think about public ip and mysql load for example), and checks that are using such data. Then such a agent can be a great asset for your monitoring platform.
No more plugins problems
The agent can schedule its own checks, and will forward to shinken only the state changes. With such a low brandwith system, you can launch far more checks than now, and launching every checks at 10s interval will be possible.
Huge elasticity
For the second problem (lack of elasticity), when the agent is launched and did detect which OS and which applications are on the server, it can declare itself to shinken. And when it's going down, it can also inform shinken too.
How the agent works
You can have a look at such system on this picture:
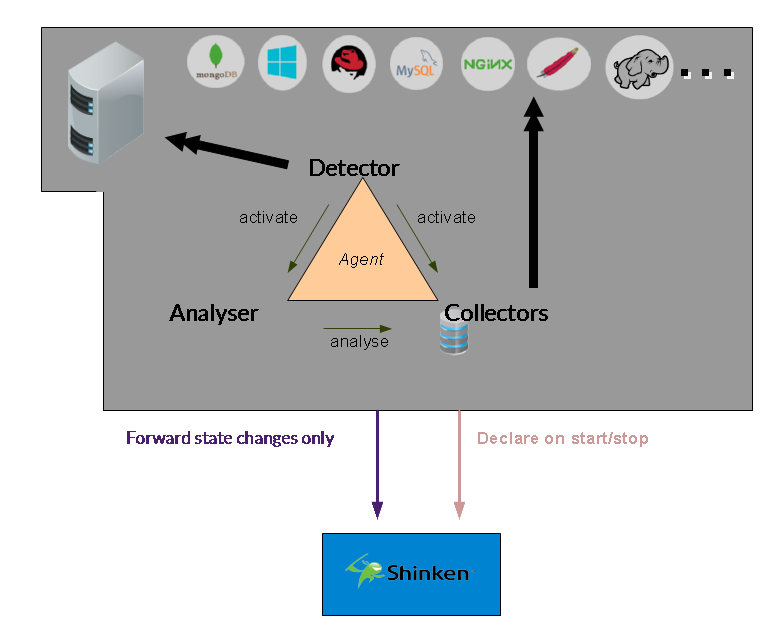
There are 3 main parts:
- The detector detects the server and the applications running on it
- The collectors grab data from both the system and the applications
- The analyser launchs checks that look if all is going well on both your system and your applications
The key in separated collectors and checks is that you don't have to keep the same interval betweek collect and checks.
Configuration managment
Of course the local configuration did make NRPE-like solution nightmare to maintain. That's why I propose to use the solution that I already propose in Shinken Enterprise: do not manage the configuration in a definition way, but in a rule-based one. For example:
- is redis installed on your system? => you are a redis server
- is it a windows running? => activate windows collectors and checks
- is you public ip in the EC2-East range? => warn the good administrators
- ...
With such a way, all agents will have the same rules, but will behave locally like they should.
In the end the solution is quite great: when you add the agent on your servers, you don't need to manage your configuration anymore!
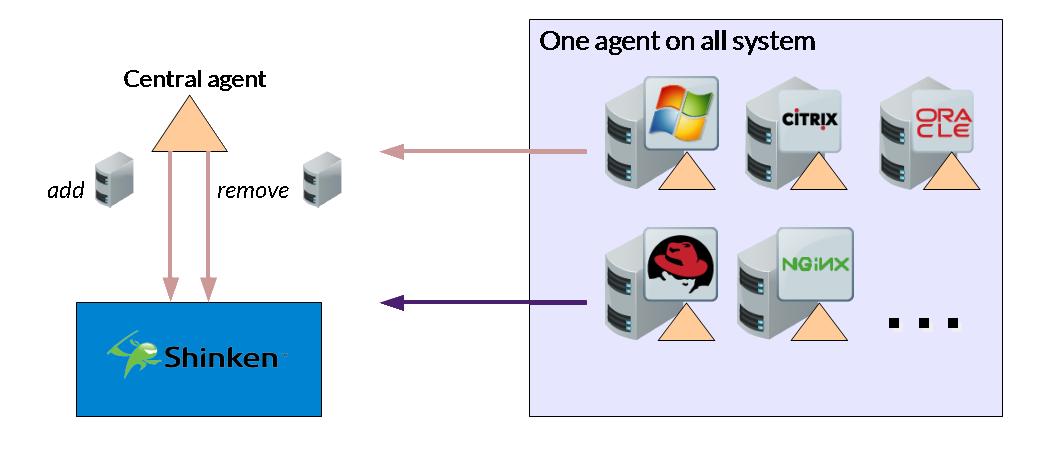
- You are launching a new server? It will be declared in few seconds into shinken with the proper tags (windows, iis for example)
- You will reduce a lot the number of pollers in your setups or increase a lot your networking mononitoring interval.
- "Out of the box" monitoring with the good detector and collectors rules :)
Feedbacks welcomed :)
You can't solve all your monitoring with agent, like you can't solve it all with only polling. You must use both to have a complete and scalable solution.
This is currently a work in progress, I'm proposing such ideas. I'm very interested about your comments about all of this (づ。◕‿‿◕。)づ




comments powered by Disqus


